
本文介绍了OpenAI在今日凌晨发布的全新音频模型,涵盖其特点、性能提升、价格以及开发应用等方面的内容,还提及了未来的发展计划。


如今,你已经能够对GPT - 4o的说话方式进行指导了。就在今天凌晨,OpenAI突然开启了一场新产品发布直播,而此次发布的新内容全部围绕音频模型展开。
据相关介绍,这些新的音频模型达到了新的SOTA(最先进技术)水平。在准确性和可靠性方面,它们要优于现有的解决方案。特别是在一些复杂场景中,比如存在口音、嘈杂环境以及不同语速的情况下,其优势更为明显。这些改进大大提高了语音/文本转录应用的可靠性,使得新模型非常适合客户呼叫中心、会议记录转录等实际应用场景。
基于全新的API,开发人员首次可以指示文本转语音模型以特定的方式说话。例如,能够让AI“像富有同情心的客户服务人员一样说话”。这为语音智能体开启了全新的定制化维度,能够实现各种各样的定制应用程序。
OpenAI还开放了一个网站(https://www.openai.fm/ ),在这里你可以直接测试音频大模型的能力。
早在2022年,OpenAI就推出了第一个音频模型,并且一直在努力提升这些模型的智能性、准确性和可靠性。借助新的音频模型及API,开发人员能够构建更准确、更强大的语音转文本系统,以及富有表现力、个性十足的文本转语音声音。
具体而言,新的gpt - 4o - transcribe和gpt - 4o - mini - transcribe模型与原始的Whisper模型相比,显著改进了单词错误率,提升了语言识别和准确性。
gpt - 4o - transcribe在多个既定基准测试中,展现出比现有Whisper模型更好的单词错误率(WER)性能,实现了语音转文本技术的重大突破。这些进步得益于强化学习创新,以及使用多样化、高质量音频数据集进行的大量中期训练。
这些新的语音 - 文本模型能够更好地捕捉语音的细微差别,减少误认情况的发生,提高转录的可靠性。尤其是在涉及口音、嘈杂环境和不同语速的具有挑战性的场景中,表现更为出色。
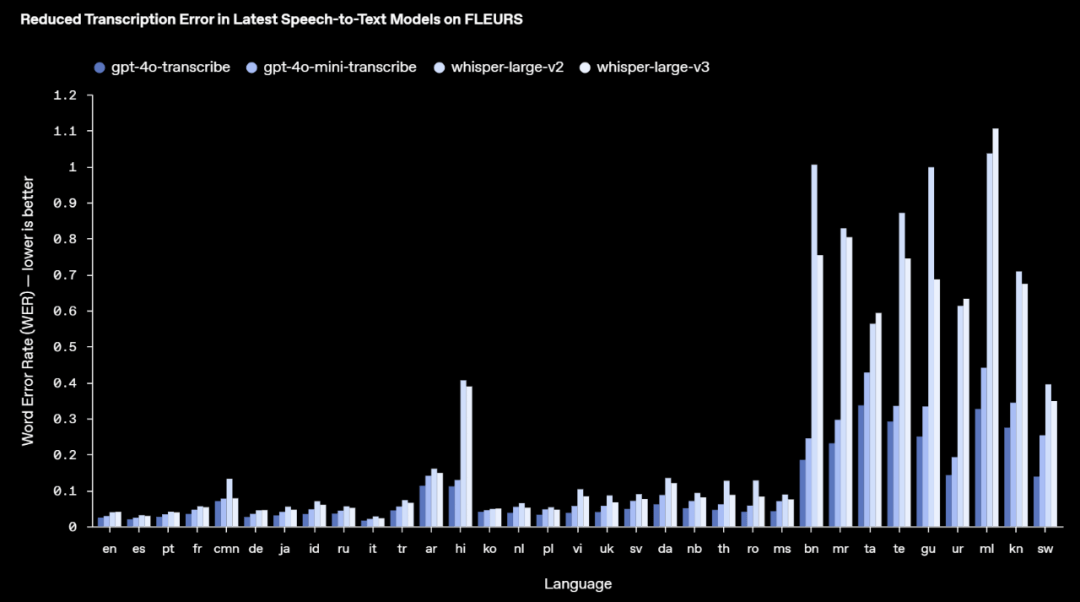
下面展示了几种模型的单词错误率(越低越好)。

在FLEURS测试中,OpenAI的模型实现了更低的WER,并且展现出强大的多语言性能。WER越低,意味着错误越少。
OpenAI还推出了一个可操纵性更好的新gpt - 4o - mini - tts模型。在这个模型上,开发人员首次可以“指导”模型,不仅能够决定模型说什么,还能决定模型怎么说,从而为大量的应用场景提供更加定制化的体验。该模型可在text - to - speech API中使用。不过目前,这些文本转语音模型仅限于人工预设的声音,并且受到OpenAI的监控。
就在昨天,OpenAI推出的“最贵大模型API”o1 - pro API还因为每百万token收费600美元而遭到了AI社区的广泛吐槽。不过今天OpenAI推出的三款语音API价格保持了业界平均水准:gpt - 4o - mini - tts的百万token文本输入价格是0.60美元,音频输出价格为12.00美元;gpt - 4o - transcrib文本输入价格是2.50美元,音频输入价格10.00美元,音频输出价格6.00美元;gpt - 4o - mini - transcribe的文本输入价格是1.25美元,音频输入价格5.00美元,音频输出价格3.00美元。因此,今天的发布受到了人们的欢迎。

OpenAI的新音频模型基于GPT‑4o和GPT‑4o - mini架构,并且在专门的以音频为中心的数据集上进行了广泛的预训练,这对于优化模型性能起着至关重要的作用。这种有针对性的方法能够让模型更深入地了解语音细微差别,在与音频相关的任务中实现出色的性能。
在模型训练过程中,OpenAI增强了提炼技术,将知识从最大的音频模型转移到了更小、更高效的模型上。利用先进的自我博弈方法,OpenAI的提炼数据集有效地捕捉了真实的对话动态,复制了真正的用户助手交互,这有助于小型模型提供出色的对话质量和响应能力。
OpenAI的语音转文本模型集成了大量强化学习,将转录准确性推向了最先进的水平。据称,这种方法大大提高了精度并减少了幻觉,使语音转文本解决方案在复杂的语音识别场景中具有极强的竞争力。
这些发展代表了音频建模领域的进步,将创新方法与实用增强功能相结合,以增强语音应用程序的性能。
这些新的音频模型现在可供所有开发人员使用,具体可参考链接:https://platform.openai.com/docs/guides/audio 。

对于已经使用基于文本的模型构建对话体验的开发人员来说,添加OpenAI语音转文本和文本转语音模型是构建语音智能体的最简单方法。OpenAI发布了与Agents SDK的集成以简化此开发过程。对于希望构建低延迟语音转语音体验的开发人员,OpenAI建议使用Realtime API中的语音转语音模型进行构建。
在未来,OpenAI计划继续提升音频模型的智能性和准确性,并且探索允许开发人员使用自定义声音构建更加个性化体验的方法。包括视频等更多模态的能力也正在研发过程当中。
本文详细介绍了OpenAI凌晨发布的新音频模型,其在准确性、可靠性和可定制性上有显著提升,价格合理,且应用开发便捷。新模型基于特定架构和数据集训练,集成强化学习技术。未来,OpenAI还将持续优化并拓展其功能。这些发展代表了音频建模领域的重要进步,为语音应用的发展带来了新机遇。
原创文章,作者:东海凝丝,如若转载,请注明出处:https://www.gouwuzhinan.com/archives/40600.html