
本文围绕DeepSeek本地化部署展开,介绍了其优势以及用户在选择适合硬件版本时的困扰。通过使用RTX 50系的四张显卡进行实测,对比不同显卡在运行DeepSeek模型时的性能表现,分析显存和算力对模型运算的影响,并总结出相关要点。
在当今的科技领域,DeepSeek本地化部署成为了备受关注的热门应用方式。这种部署方式有着显著的优势,一方面,它能够避免服务器繁忙所带来的各种问题,确保运行的流畅性;另一方面,本地化运行可以在极大程度上保护用户的隐私,让用户的数据更加安全可靠。
目前,DeepSeek拥有众多不同的版本,而且这些版本之间的模型容量差距非常大,可达数十倍之多。这就使得用户在选择适合自己硬件的版本来进行部署时,面临着诸多困扰,一直是大家比较头疼的问题。


为了帮助大家更好地了解不同显卡在运行DeepSeek模型时的性能表现,今天我们专门选用了四张RTX 50系显卡,分别是RTX 5090 D、RTX 5080、RTX 5070 Ti以及RTX 5070,来进行一次实测,看看它们之间的性能差距究竟如何。
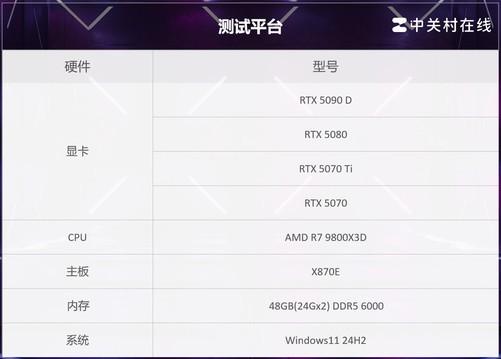 首先,给大家介绍一下本次的测试平台。除了上述四张参与测试的显卡之外,处理器我们选择了AMD R7 9800X3D,内存则使用的是48GB DDR5 6000MHz。关于本地部署的具体步骤,在这里我们就不再过多讲解了,有兴趣的用户可以翻看我们此前发布的相关文章。
首先,给大家介绍一下本次的测试平台。除了上述四张参与测试的显卡之外,处理器我们选择了AMD R7 9800X3D,内存则使用的是48GB DDR5 6000MHz。关于本地部署的具体步骤,在这里我们就不再过多讲解了,有兴趣的用户可以翻看我们此前发布的相关文章。
在本次测试中,我们使用LM Studio进行测试,并且不采用任何加速框架,完全依靠显卡自身的算力来进行对比。这是因为不同的加速框架对不同厂商的显卡优化程度不同,如果使用加速框架,测试变量会太大,不利于得出准确的测试结果。
我们首先选择了【DeepSeek R1 Distill Qwen 32B】模型来进行测试。
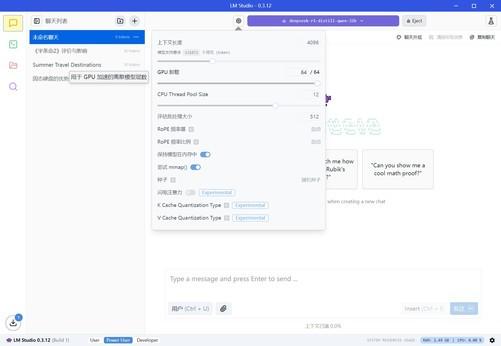
在测试过程中,我们将GPU卸载拉满,这意味着DeepSeek模型的所有计算都将完全由GPU来完成,其他参数则保持默认即可。由于AI模型每次给出的回答都会有所不同,为了得到更准确的结果,我们设置了3个问题,然后取平均值。
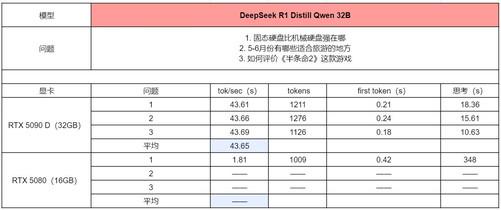
另外,需要特别注意的是,我们设置的问题本身是有一定范围限制的,这样可以让AI在思考和回答问题时不会过于发散。如果问一些像“什么是哲学”这类没有明确范围的问题,每次回答的结果将很难进行量化分析。
在使用32B模型进行测试时,可以明显看到RTX 5090 D的tok/sec速度非常快。毕竟它作为本代的旗舰产品,拥有32GB的大显存,这种大显存本身就非常适合进行AI训练。
然而,当我们使用RTX 5080进行测试时,却出现了问题。可以看到,RTX 5080在回答问题时,思考时间达到了348秒,也就是将近6分钟。
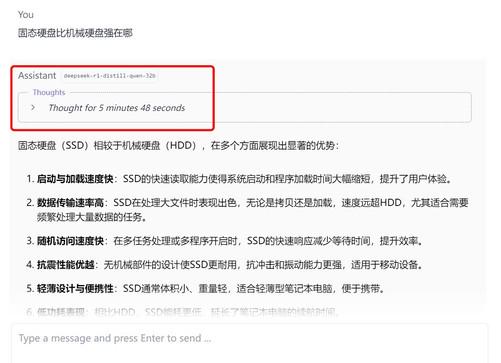
这里需要给大家提及一下,不同模型对于显存需求的换算大致有一个公式,即:(32)B÷2×1.15 = 显存。所以,32B模型所需要的最低显存大约为18.4GB左右,而RTX 5080的显存只有16GB,这就意味着显存已经超出了RTX 5080的承受范围。超出的这2GB显存,则需要由内存来补足。
但是,对于模型来说,一旦出现爆显存的情况,不管从内存“外借”多少,都将按照最慢的速度进行运算。实测同事的RTX 2060,在运行32B模型时,即便“外借”的内存更多,但思考时间同样在5分钟左右。
 由于爆显存的情况会对测试结果产生较大影响,使得本次测试的意义不大,所以我们决定更换更小的8B模型,这样后续的显卡型号就都能够完全用显存来完成测试了。
由于爆显存的情况会对测试结果产生较大影响,使得本次测试的意义不大,所以我们决定更换更小的8B模型,这样后续的显卡型号就都能够完全用显存来完成测试了。
根据上面的公式,我们可以推测出8B模型大约只需要4.6GB的显存,就可以满足其运算需求。
 在更换模型之后,所有的显卡都可以进行正常测试了,测试成绩汇总如下。
在更换模型之后,所有的显卡都可以进行正常测试了,测试成绩汇总如下。
从测试结果来看,tok/sec与显卡的显存以及算力有着较大的关系,并且呈现出应有的性能递进关系。而first token和思考时间则没有太大的规律可循。为了让大家能够更清晰地看到每张显卡的tok/sec成绩,我们将其进行了柱状图汇总。
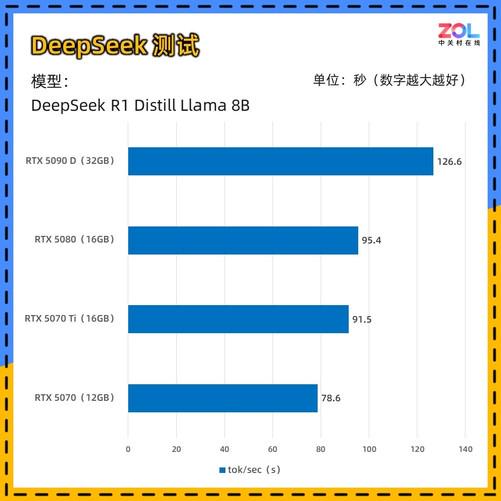
不出所料,拥有大显存和高算力的RTX 5090 D在测试中拔得头筹。而显存相同的RTX 5080及RTX 5070 Ti之间的差距并不大。根据不同显卡之间的AI算力来看:RTX 5090 D(AI TOPS:2375);RTX 5080(AI TOPS:1801);RTX 5070 Ti(AI TOPS:1406);RTX 5070(AI TOPS:988)。
由此可以看出,至少对于DeepSeek大语言模型来说,对AI算力的要求并不是最重要的,显存才是关键因素。只要显存足够大,在进行推理运算时就会具有压倒性的优势。
最后,我们来总结一下本次DeepSeek测试的要点,方便大家快速记忆:
1. DeepSeek大语言模型对GPU的需求:显存>算力。
2. 模型对显存要求的换算公式(x)B÷2×1.15 = 显存。
3. 当显存无法满足模型的最低需求时,再多的AI算力都无济于事。
4. 思考时间与GPU并没有绝对的关系,而是与问题的开放性有关。
本次测试选择LM Studio,目的就是为了使用显卡未经加速的真实算力。不过,现在市面上有很多针对不同架构的加速框架,甚至笔记本也能够跑满血大模型,大家在自己使用时不妨自行尝试一下。
本文通过对DeepSeek本地化部署的介绍,引出使用RTX 50系显卡进行实测的内容。详细阐述了测试过程、不同显卡在不同模型下的表现,分析得出DeepSeek大语言模型对显存的需求大于算力,以及显存不足时算力作用有限等结论,还给出了模型显存需求换算公式和思考时间的影响因素,并鼓励用户尝试加速框架。
原创文章,作者:Daniel Adela,如若转载,请注明出处:https://www.gouwuzhinan.com/archives/44165.html